NUMERISER VOS TEXTES (par Ebooks libres et gratuits - ELG)
Numériser du texte est très facile, vous trouverez, dans ce tutoriel, quelques conseils pour rendre votre travail plus facile, plus rapide et éviter la répétition de gestes inutiles. En fait la numérisation des textes, telle que nous la pratiquons, se devise deux étapes :
- La numérisation proprement dite, c'est à dire la photocopie numérique à l'aide d'un scanner, qui va produire un ensemble d'images numériques (par exemple aux formats PDF, ou TIFF multipages, voire en JPG)
- La reconnaissance de caractères, l'OCR (nous utiliserons ce terme, plus court, ensuite), qui est l'extraction du texte, de l'image numérique, grâce à un logiciel spécialisé.
La numérisation : le scanner
Tout
scanner à plat peut-être utilisé pour la numérisation, la plupart ont une
définition de 1200 dpi et nous n’utiliserons qu’une définition de 300 dpi (les divers tests effectués montrent qu'une définition supérieure donne des résultats égaux, ou inférieurs...), en noir et blanc (l'utilisation des niveaux de gris ou de la couleur devra être strictement réservée aux pages comportant des illustrations qui le nécessitent - pour les illustrations en noir et blanc, faire un test en noir et blanc, avant d'adopter les niveaux de gris). Cette recommandation de se limiter à 300 dpi, noir et blanc, est motivée par deux choses :
* Obtenir le meilleur résultat possible lors de l'OCR.
* Obtenir des fichiers les moins volumineux possible.
Nul besoin d’un scanner de qualité photo, un vieux scanner d’occasion suffit (attention au pilote). Par contre, si vous devez scanner de nombreux livres, et êtes à l'aise financièrement, la vitesse de scan sera un argument important...

Placez votre livre ouvert à la première page (dans l'hypothèse où le livre ouvert est inférieur ou égal à la taille A4) en calant le livre dans un des coins, toujours le même (le fait que le livre soit toujours au même endroit de la vitre est important pour la suite). Nous allons donc scanner deux pages d'un coup.

Il est important, dans la mesure du possible, que le livre soit bien plaqué contre la vitre ; vous pouvez, par exemple, ajouter le poids d'un autre livre, ou tout simplement appuyer avec les mains. Attention tout de même à ne pas abîmer la reliure si vous tenez à ce livre...
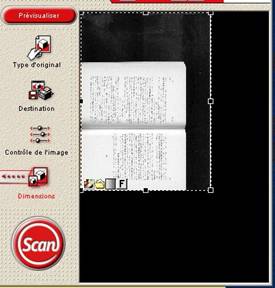
Faites une première prévisualisation, sélectionnez toute la surface de la vitre
L'important est de bien régler la luminosité et/ou le contraste. Par exemple, si vous ne pouvez pas plaquer parfaitement le livre sur la vitre, à cause de la reliure, il faut souvent «éclaircir», de façon à ce que la séparation entre les pages, correspondant à la reliure, ne produise pas un énorme trait noir, non seulement inesthétique, mais qui pourrait induire en erreur l'OCR. Il faut que les caractères soient bien visibles, mais il ne sert à rien d'augmenter trop le contraste, pour avoir des caractères «très noirs»: non seulement l'OCR ne sera pas plus efficace, mais les «saletés» diverses qu'on peut trouver sur des livres d'occasion, voire les simples rousseurs, seraient alors «mises en valeur» et pourraient tromper le moteur d'OCR.
Créez un répertoire qui recevra vos images. Lancer la numérisation donnez un nom à votre fichier et un numéro de préférence, pour garder l’ordre des pages (n’oubliez pas de mettre des zéros devant : 001, 002, 003 etc.).
En ce qui concerne les formats d'enregistrement des images, nous vous conseillons les formats PDF ou TIFF multipages. À défaut, vous pouvez choisir le format JPG.
Tournez la page, et lancez à nouveau la numérisation sans prévisualisation, nous avons sélectionné toute la surface du scanner afin de l’utiliser un peu comme une photocopieuse et d’éviter la prévisualisation. Mais n'oubliez pas, quand même, de toujours placer le livre au même endroit de la vitre.
Nous vous conseillons de ne pas numériser plus 80-100 pages par séance, soit 40 à 50 passes de scanner pour les livres de taille inférieure au demi A4 - du moins avec un scanner basique, car cela devient vite fastidieux, et le scanner chauffe. Mais il faut noter qu'un de nos membres bien connu, qui a la chance de disposer d'un scanner professionnel de haut niveau, scanne sans problème 400 pages en une heure (c'est à dire 200 passes de scanner).
Si votre scan est uniquement destiné à être «océrisé», il est inutile de recadrer ou de faire pivoter les images, car les logiciels OCR reconnaissent généralement le sens du texte, les colonnes et s’il y a une ou plusieurs pages. Par contre, si vous désirez, par exemple, publier également l'image scannée, qui peut avoir un grand intérêt dans le cas de vieux livres, il faudra alors faire un travail de rotation, recadrage, etc de la page (manipulations qui débordent le cadre du présent article), et vous apprécierez alors grandement d'avoir suivi nos conseils concernant le placement du livre sur la vitre.
La reconnaissance de caractères ou l’OCR
Plusieurs logiciels existent : Readiris, Omnipage, FineReader ; et pour ceux qui ont le pack office XP ou 2003, il est inclus, dans les outils Microsoft Office, «Document Scanning».
Mais, après de nombreux tests, la quasi-totalité des membres de notre groupe a adopté FineReader (versions 7 ou 8), qui se révèle supérieur aux autres, à cause d'un tas de «détails» qu'il serait un peu long d'énumérer ici.
Prenons l'exemple de FineReader 7. Si dans l’avenir vous utilisez un autre logiciel vous ne serez pas dépaysé l’interface est à peu près identique pour tous ces programmes.
Nous vous conseillons de tout de suite enregistrer votre «Lot sans titre», et donc de conserver vos lots FineReader ; le lot FineReader est en fait un dossier caché, du même nom que celui que vous avez donné au lot, et situé à l'endroit où vous avez enregistré le lot; il est donc facile de déplacer, sauvegarder ce lot (pour une sauvegarde, nous vous conseillons de zipper le dossier caché, pas son contenu, le dossier lui-même).
Si vous travaillez pour Ebooks libres et gratuits, il faut utiliser les options qui apparaissent sur cette page (les options FineReader 8 sont en bas de la page). Pour FineReader 7, il faut, malheureusement, mettre ces options pour chaque nouveau lot. Pour FineReader 8, ces options peuvent être mises par défaut pour tous les nouveaux lots, si vous le désirez. Ces options conviennent pour les livres non illustrés (en effet, les images ne sont pas conservées dans les sortie Word). Pour les livres illustrés, certaines de ces options doivent donc être modifiées, mais des corrections manuelles trop longues à expliquer ici sont également souvent nécessaires, pour les pages illustrées, après la phase de reconnaissance, corrections qui obligent à une nouvelle reconnaissance des pages modifiées.
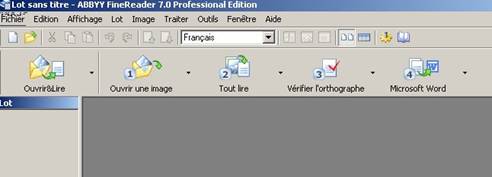
Cliquer sur l’icône «Ouvrir et lire» (ou cliquer sur «Ouvrir une image», puis, quand toutes les images sont ouvertes, cliquer sur «Tout lire»).
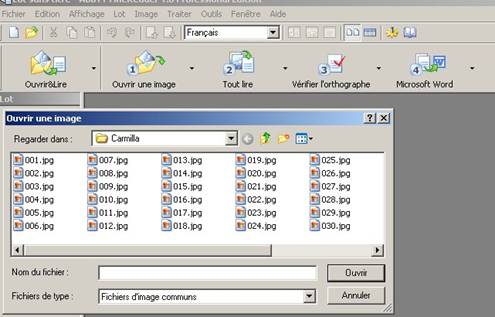
Sélectionnez les images que vous voulez reconnaître (ctrl + a pour toutes ou ctrl + clic gauche pour les sélectionner les unes après les autres). Nous avons ici des images JPG, une par page, mais nous pourrions avoir un fichier PDF ou TIFF multipage par séance de scan.
FineReader va donc ouvrir puis reconnaître chaque image. Évidemment le temps variera selon le nombre d’images à traiter.
Une fois la reconnaissance effectuée, il ne reste que la dernière étape, le bouton 4 dans la figure ci-dessus, dont le libellé va changer selon le choix que vous effectuerez en cliquant sur la petite flèche à droite du bouton. Cela peut être, par exemple :
- Microsoft Word, c'est à dire l'envoi dans Word du contenu texte obtenu par l'OCR
- Enregistrer, pour l'assistant d'enregistrement qui offre notamment la possibilité de sortir un PDF image indexé, c'est à dire PDF image avec le texte d'OCR brut présent, invisible, sous l'image, mais utilisable pour effectuer des recherches texte ou pour un copier-coller.
Ce sont ces deux dernières possibilités qui sont utilisées par les membres de ELG.
Vous pouvez aussi faire une reconnaissance de caractères à partir des documents images de la bibliothèque nationale sur le site Gallica BNF.
La correction
Le principe est tout simplement de comparer mot à mot le document PDF image indexé et le document Word, et de corriger ce dernier en se conformant exactement au contenu du PDF. Pour cela, il suffit de mettre ensemble, sur l'écran, les deux documents, en se débrouillant pour trouver une taille de fenêtre adéquate. Cela peut représenter un gros travail si le scan a été mal fait ou s'il s'agit d'un vieux livre comme on en trouve parfois sur Gallica. Pour faciliter le travail, il est conseillé de mettre en forme le texte Word préalablement, nous avons des macros Word pour cela (s'adresser à Jean-Marc ou Coolmicro)
Il faut noter que certains, préfèrent effectuer la correction directement dans FineReader, qui offre la possibilité de mettre côte à côte le texte et l'image, et sortir le doc Word ensuite. C'est une question de goût, aucune des deux méthodes n'étant meilleure en soi.